, 3 min read
Memory-level parallelism: Intel Skylake versus Apple A12/A12X
Modern processors execute instructions in parallel in many different ways: multi-core parallelism is just one of them. In particular, processor cores can have several outstanding memory access requests “in flight”. This is often described as “memory-level parallelism”. You can measure the level of memory-level parallelism your processors has by traversing an array randomly either by following one path, or by following several different “lanes”. We find that recent Intel processors have about “10 lanes” of memory-level parallelism.
It has been reported that Apple’s mobile processors are competitive (in raw power) with Intel processors. So a natural question is to ask whether Apple’s processors have more or less memory-level parallelism. The kind of memory-level parallelism I am interested in has to do with out-of-cache memory accesses. Thus I use a 256MB block of memory. This is large enough not to fit into a processor cache. However, because it is so large, we are likely to suffer from a virtual-memory-related fault. This can significantly limit memory-level parallelism if the page sizes are too small. By default on the Linux distributions I use, the pages span 4kB (whether on 64-bit ARM or x64). Empirically, that is too small. Thankfully, it is easy to reconfigure the pages so that they span 2MB or more (“huge pages”). On Apple’s devices, whether it be an iPhone or an iPad Pro, I believe that the pages always span 16kB and that this cannot be easily reconfigured.
Before I continue, let me present the absolute timings (in second) using a single lane (thus no memory-level parallelism). Apple makes two version of its most recent processor, the A12 (in the iPhone) and the A12X (in the iPad Pro).
| Intel skylake (4kB pages) | 0.73 s |
|---|---|
| Intel skylake (2MB pages) | 0.61 s |
| Apple A12 (16kB pages) | 0.96 s |
| Apple A12X (16kB pages) | 0.97 s |
| Apple A10X (16kB pages) | 1.15 s |
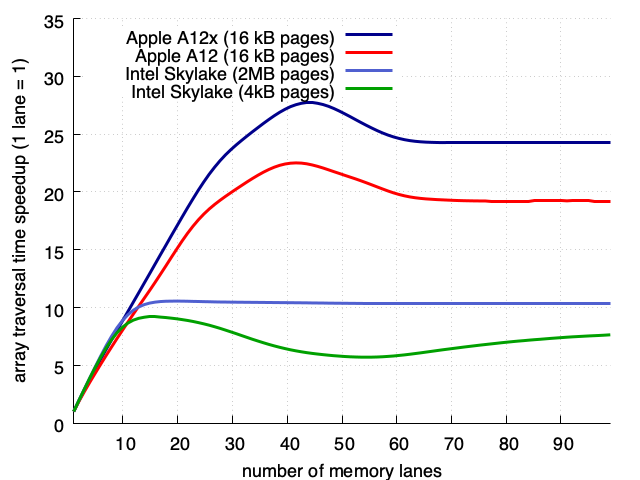
According to these numbers, the Intel server has the upside over the Apple mobile devices. But that’s only part of the story. What happens as you increase the number of lanes (while keeping the code single threaded) is interesting. As you increase the number of lanes, Apple processors start to beat the Intel Skylake in absolute, raw speed.

Another way to look at the problem is to measure the “speedup” due to the memory-level parallelism: we divide the time it takes to traverse the array using 1 lane by the time it takes to do so using X lane. We see that the Intel Skylake processor is limited to about a 10x or 11x speedup whereas the Apple processors go much higher.
Thoughts:
- I’d be very interested in knowing how Qualcomm and Samsung processors compare.
- It goes without saying that my server-class Skylake machine uses a lot more power than the iPhone.
- If I could increase the page size on iOS, we would get even better numbers for the Apple devices.
- The fact that the A12 has higher timings when using a single lane suggests that its memory subsystem has higher latency than a Skylake-based PC. Why is that? Could Apple just crank up the frequency of the DRAM memory and beat Intel throughout?
- Why is Intel limited to 10x memory-level parallelism? Why can’t they do what Apple does?
Credit: I owe much of the design of the experiment and C++ code to Travis Downs, with help from Nathan Kurz. The initial mobile app for Apple devices was provided by Benoît Maison, you can find it on GitHub along with the raw results and a “console” version that runs under macOS and Linux. I owe the A12X numbers to Stuart Carnie and the A12 numbers to Victor Stewart.
Further reading: Memory Latency Components