, 5 min read
Cloudflare Dashboard Down
Original post is here eklausmeier.goip.de/blog/2023/11-02-cloudflare-dashboard-down.
This blog is self-hosted. One could think that this situation is particularly prone to outages. Actually, this hosting is quite stable compared to professional services. This to my own surprise. Press the green button at the top to see all the outages of this blog.
Today Cloudflare has its snafu-moments:
Cloudflare is assessing a loss of power impacting data centres while simultaneously failing over services.
So even the biggest players in the pond suffer from power outage from time to time.
The following products are currently impacted at the data plane / edge level, meaning that the full product functionality is either partially or fully affected: Logpush, WARP / Zero Trust device posture, Cloudflare dashboard, Cloudflare API, Stream API, Workers API, Alert Notification System.
As I have a copy of this blog on Cloudflare Workers, I cannot update my blog, at least not today.
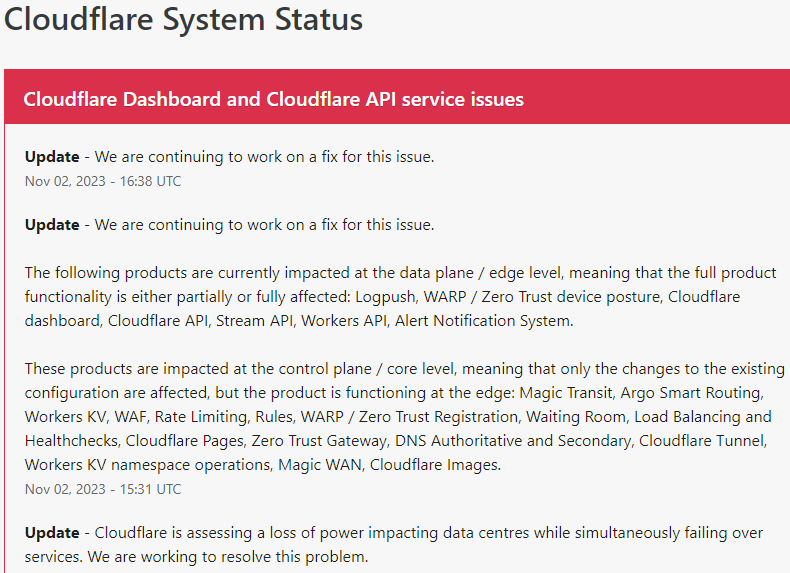
Uploading a zip-file also does not work.
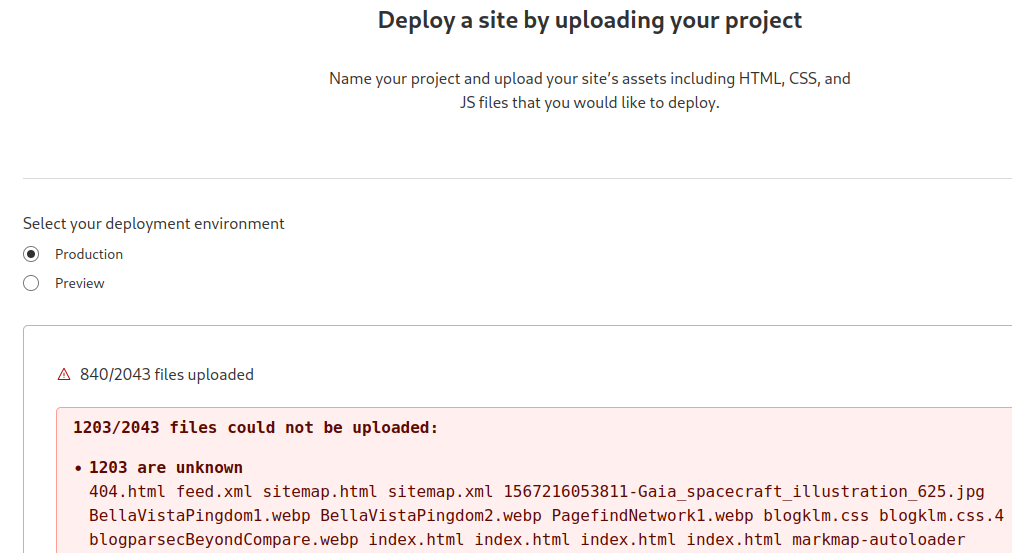
Added 03-Nov-2023: Cloudflare was hit really hard. Now their dashboard is entirely unavailable.
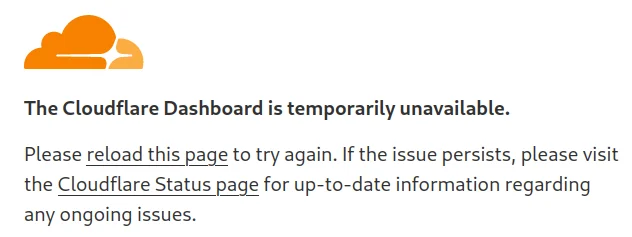
Text:
The Cloudflare Dashboard is temporarily unavailable.
Please reload this page to try again. If the issue persists, please visit the Cloudflare Status page for up-to-date information regarding any ongoing issues.
It looks that they didn't fully realize how severe their problem really is.
Added 05-Nov-2023: On 04-Nov-2023 Matthew Prince, CEO of Cloudflare, gave a detailed post mortem of the incident. The text Post Mortem on Cloudflare Control Plane and Analytics Outage is worth reading multiple times. It teaches a number of important lessons in resilience. Here I will quote some snippets, party out of context, but highlighting some of the many problems.
The largest of the three facilities in Oregon is run by Flexential.
The mishap started as follows:
On November 2 at 08:50 UTC Portland General Electric (PGE), the utility company that services PDX-04, had an unplanned maintenance event affecting one of their independent power feeds into the building.
This happened without Cloudflare being aware of this. I had already speculated that Cloudflare was not really aware of their mess they were in:
Flexential did not inform Cloudflare that they had failed over to generator power. None of our observability tools were able to detect that the source of power had changed.
Things get worse quite quickly:
At approximately 11:40 UTC, there was a ground fault on a PGE transformer at PDX-04. ... Ground faults with high voltage (12,470 volt) power lines are very bad. Electrical systems are designed to quickly shut down to prevent damage when one occurs. Unfortunately, in this case, the protective measure also shut down all of PDX-04’s generators. This meant that the two sources of power generation for the facility — both the redundant utility lines as well as the 10 generators — were offline.
One mishap doesn't come alone:
PDX-04 also contains a bank of UPS batteries. ... the batteries started to fail after only 4 minutes.
As if it was written by a film author:
the overnight shift (from Flexential) consisted of security and an unaccompanied technician who had only been on the job for a week.
Data center went dark without Cloudflare knowing it:
Between 11:44 and 12:01 UTC, with the generators not fully restarted, the UPS batteries ran out of power and all customers of the data center lost power. Throughout this, Flexential never informed Cloudflare that there was any issue at the facility.
The rest of the text discusses why Cloudflare put some of their production products into a single data center, in this case the faulty one.
We were also far too lax about requiring new products and their associated databases to integrate with the high availability cluster.
But the nightmare was not over yet:
At 12:48 UTC, Flexential was able to get the generators restarted. ... When Flexential attempted to power back up Cloudflare's circuits, the circuit breakers were discovered to be faulty.
The next sentence tells you why you should always have enough spare replacement kits:
Flexential began the process of replacing the failed breakers. That required them to source new breakers because more were bad than they had on hand in the facility.
Thundering herd problem, also see Josep Stuhli On Scaling to 20 Million Users:
When services were turned up there, we experienced a thundering herd problem where the API calls that had been failing overwhelmed our services.
Always test your disaster recovery procedures, if not, then:
A handful of products did not properly get stood up on our disaster recovery sites. These tended to be newer products where we had not fully implemented and tested a disaster recovery procedure.
Cloudflare's data center reported normal operations:
Flexential replaced our failed circuit breakers, restored both utility feeds, and confirmed clean power at 22:48 UTC.
But for Cloudflare the ordeal was not over yet. The had to restart everything:
Beginning first thing on November 3, our team began restoring service in PDX-04. That began with physically booting our network gear then powering up thousands of servers and restoring their services. The state of our services in the data center was unknown as we believed multiple power cycles were likely to have occurred during the incident. Our only safe process to recover was to follow a complete bootstrap of the entire facility.
This was no small feat:
Rebuilding these took 3 hours.
Matthew Prince acknowledges that much is to be learnt from this event:
But we also must expect that entire data centers may fail. Google has a process, where when there’s a significant event or crisis, they can call a Code Yellow or Code Red. In these cases, most or all engineering resources are shifted to addressing the issue at hand.
We have not had such a process in the past, but it’s clear today we need to implement a version of it ourselves
Little gold nugget from the lessons learnt:
Test the blast radius of system failures
Murphy's law applies universally, in particular for software and data centers.
Added 18-Nov-2025: Cloudflare is down again. This time when serving client websites.
| Time | error code |
|---|---|
| 14:50 | 9a07ea5b4ee637e9 |
| 15:17 | 9a0816108e839b4c |
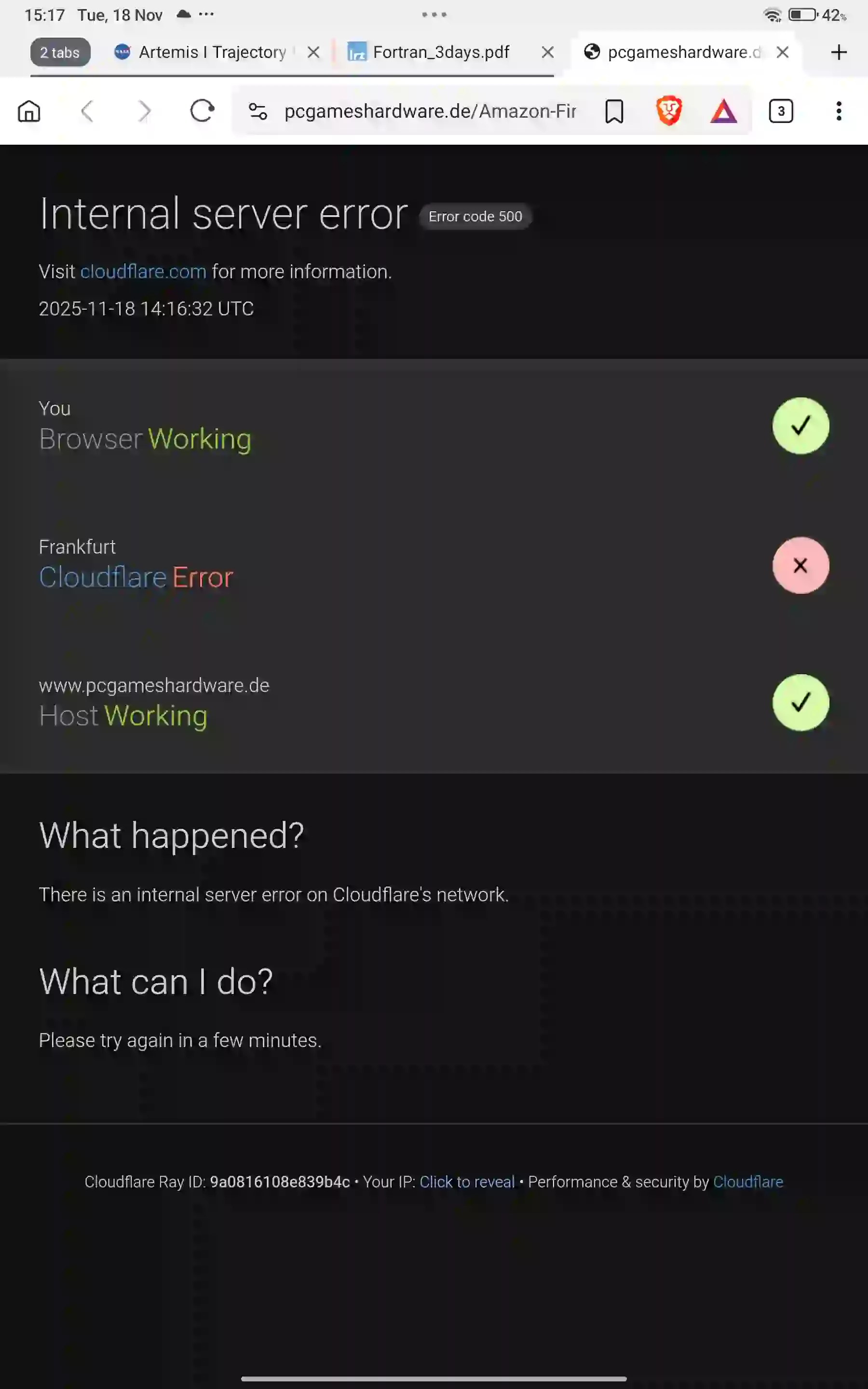
This outage was confirmed by the Cloudflare blog post "Cloudflare outage on November 18, 2025".
The outage lasted for almost six hours.
One of the culprits was a Rust program:
